

In Part 1, we built an insurance claim processor — your first real AI app with Bedrock. We called models, built prompt templates, and compared outputs side by side. Useful for learning, but not how you’d run things in production.
Now we’re leveling up. Part 1’s compare_models becomes a proper benchmarking framework. The simple retry loop becomes a circuit breaker that falls back to a different model and degrades gracefully when everything fails.
The Problem
Part 1’s approach had gaps. Picking a model by eyeballing two outputs doesn’t scale. Retrying the same failing model three times doesn’t help if the model is down. Changing models means editing code and redeploying. A regional outage takes your whole service offline.
This project fixes all of that.
The Pattern
This project teaches a resilience pattern that applies to any AI application:
Benchmark → Select → Invoke → Fallback → Degrade Gracefully
Same architecture works for healthcare chatbots, legal document analysis, customer support. The resilience patterns are the same.
Architecture
The system accepts customer queries through API Gateway, dynamically selects the best Bedrock model based on benchmark scores, and uses a Step Functions circuit breaker for fault tolerance. Cross-region deployment via CloudFormation and Route 53 provides regional resilience.
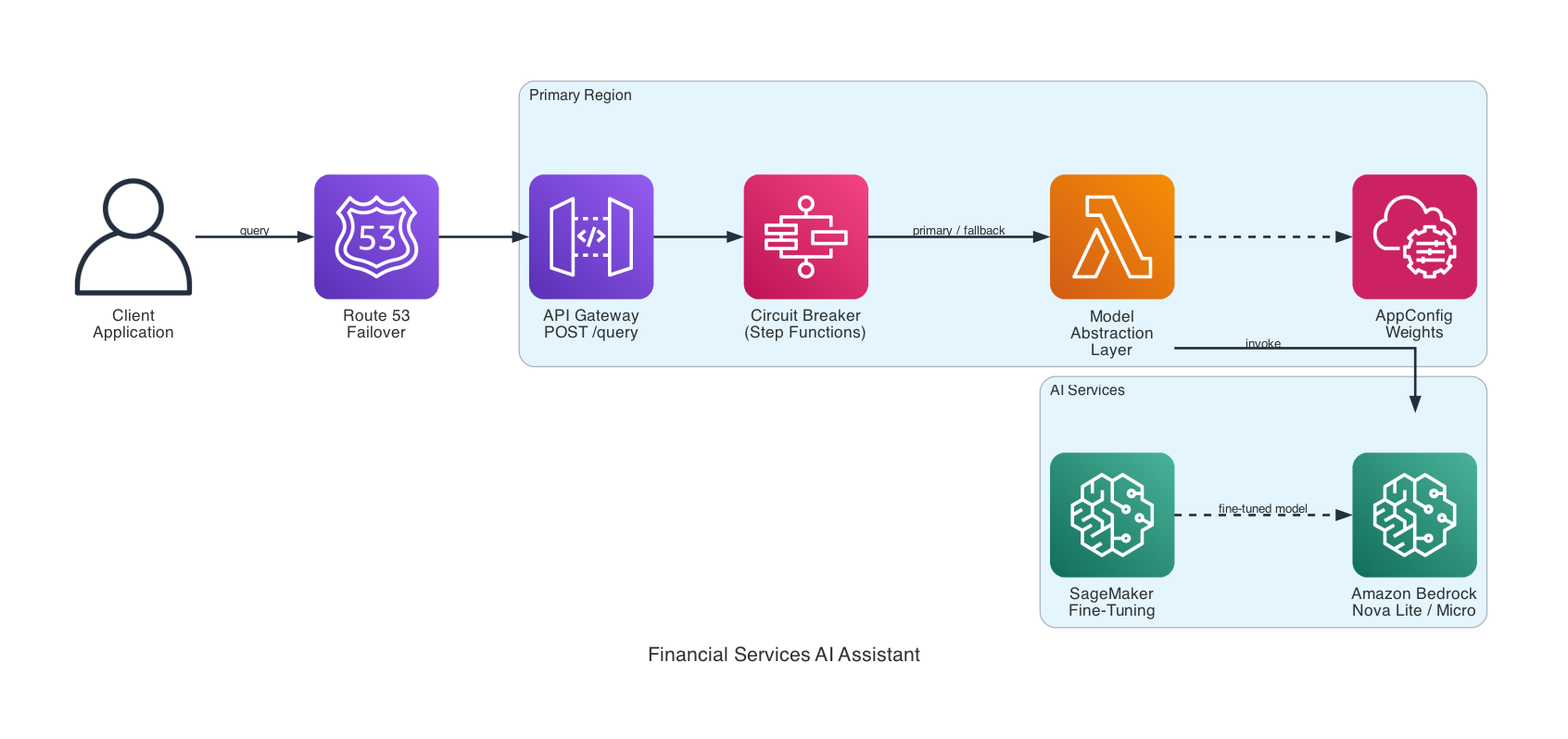
Key components:
- Benchmarking Framework — scores models on quality, latency, and cost with configurable weights
- Model Selector — picks the best model using AppConfig weights (changeable at runtime, no redeployment)
- Lambda Abstraction Layer — uniform interface for invoking any supported Bedrock model
- Circuit Breaker — Step Functions workflow: primary → fallback → graceful degradation
- Cross-Region Deployment — CloudFormation + Route 53 failover routing
How It Works
When a customer query comes in, it flows through a resilient pipeline designed to always return a response.
API Gateway. POST /query validates the request and passes it to the circuit breaker.
Model Selection. The Model Selector picks the best model based on benchmark scores and AppConfig weights. Default weights: quality 50%, latency 30%, cost 20%. Change them at runtime — no deployment needed.
Primary Attempt. The Lambda abstraction layer invokes the top-ranked model via Bedrock’s Converse API. On success, the response goes back to the client.
Fallback. If the primary model fails, the circuit breaker invokes a different fallback model. Not the same model again — a different one.
Graceful Degradation. If both models fail, the system returns a friendly message with a phone number and a Retry-After header. The customer always gets a response.
The Benchmarking Framework
Before serving any queries, you benchmark your models. The framework runs each model against financial services test prompts and scores responses on three dimensions:
- Completeness — are all expected fields present?
- Relevance — does the response address the prompt topic?
- Coherence — is the response well-structured and readable?
These combine into a quality score. Then a weighted scorer applies configurable weights across quality, latency, and cost to produce a final ranking.
Model Quality Latency Cost Score
amazon.nova-lite-v1:0 0.782 1243ms $0.000180 0.714
amazon.nova-micro-v1:0 0.695 687ms $0.000098 0.723
Winner: amazon.nova-micro-v1:0 (weighted score: 0.723)
Nova Micro wins here — faster and cheaper, and the quality gap isn’t big enough to overcome the latency and cost advantages with the default weights.
The Circuit Breaker
Part 1’s ModelInvoker retried the same model 3 times. If the model was down, you were stuck.
The circuit breaker is smarter. It’s a Step Functions Express workflow with three outcomes:
Primary model ──success──► Return response
│
failure
│
Fallback model ──success──► Return response
│
failure
│
Graceful degradation ──► "Please call 1-800-XXX-XXXX"
The customer always gets a response. Always.
Dynamic Configuration with AppConfig
In Part 1, changing models meant editing code. Here, model selection weights live in AWS AppConfig:
{
"primary_model_id": "amazon.nova-lite-v1:0",
"fallback_model_id": "amazon.nova-micro-v1:0",
"weights": {
"quality": 0.5,
"latency": 0.3,
"cost": 0.2
}
}
Want to prioritize speed over quality? Update the weights. The next request uses the new config. No deployment needed.
SageMaker Fine-Tuning
The base Nova models give generic responses. For financial services, you want the assistant to know your products, compliance language, and dispute resolution procedures.
The fine-tuning pipeline takes a JSONL training dataset (minimum 100 prompt/completion pairs of your domain-specific Q&A), validates the format, and kicks off a SageMaker training job. When the job completes, the fine-tuned model is automatically registered with the Model Selector — it gets included in future benchmark runs and can be selected as the primary model.
python3 demo.py --region us-east-1 --bucket your-training-data-bucket
What Changed from Part 1
| Concept | Part 1 | Part 2 |
|---|---|---|
| Model comparison | compare_models — eyeball two outputs |
Benchmarking framework with weighted scoring |
| Error handling | Retry same model 3 times | Circuit breaker: primary → different fallback → degradation |
| Configuration | Hardcoded model IDs | AppConfig — change at runtime |
| Deployment | Single region, run locally | CloudFormation cross-region + Route 53 failover |
| Model customization | Use models as-is | SageMaker fine-tuning pipeline |
Getting Started
Prerequisites: Python 3.10+, an AWS account with Bedrock access, AWS CLI configured. If you completed Part 1, you’re already set up.
git clone https://github.com/srikanthethiraj/financial-ai-assistant.git
cd financial-ai-assistant
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
Enable Nova Lite and Nova Micro in the Bedrock console (Model access), then run:
python3 demo.py --region us-east-1
You’ll see the full flow — benchmark, select, query, and circuit breaker demo with normal, fallback, and degradation scenarios.
What’s Next
This is Part 2 of an ongoing series. Each project builds on the last:
- Part 1 — Insurance Claim Processor: Bedrock basics, prompt templates, simple RAG
- Part 2 — Financial Services AI Assistant (this post): benchmarking, circuit breakers, cross-region resilience
- Part 3 — Customer Feedback Pipeline: multimodal data processing (text, images, audio)
- Part 4 — Knowledge Base RAG System: vector stores, embeddings, document chunking
- Part 5 — Advanced Search & Retrieval: hybrid search, reranking, query expansion
- Part 6 — AI Support Assistant with Governance: guardrails, prompt management, conversation flows
- Part 7+ — Agentic AI, enterprise integration, AI safety, optimization, testing & evaluation
In Part 3, we move beyond text-only processing and build a pipeline that handles text, images, audio, and surveys — feeding them all into foundation models.
Repository: github.com/srikanthethiraj/financial-ai-assistant
I’m Srikanth — a cloud engineer at AWS based in Austin, Texas. I learn by building, and I write about what I build. Follow along on this blog or connect with me on LinkedIn.
Comments